|
Now, I am a 3rd year master at Shenzhen International Graduate School, Tsinghua University (M.Eng.@THU’2026), supervised by Prof. Yansong Tang. I obtained my bachelor's degree from the School of Software Engineering at Tongji University in 2023. I collaborated with Dr. Yukang Gan, Dr. Yixiao Ge, Dr. Ying Shan and Dr. Zhao Yang. My current research interest lies at Agentic LLMs and MLLMs. |

|
|
|
|
* Indicates Equal Contribution |
|
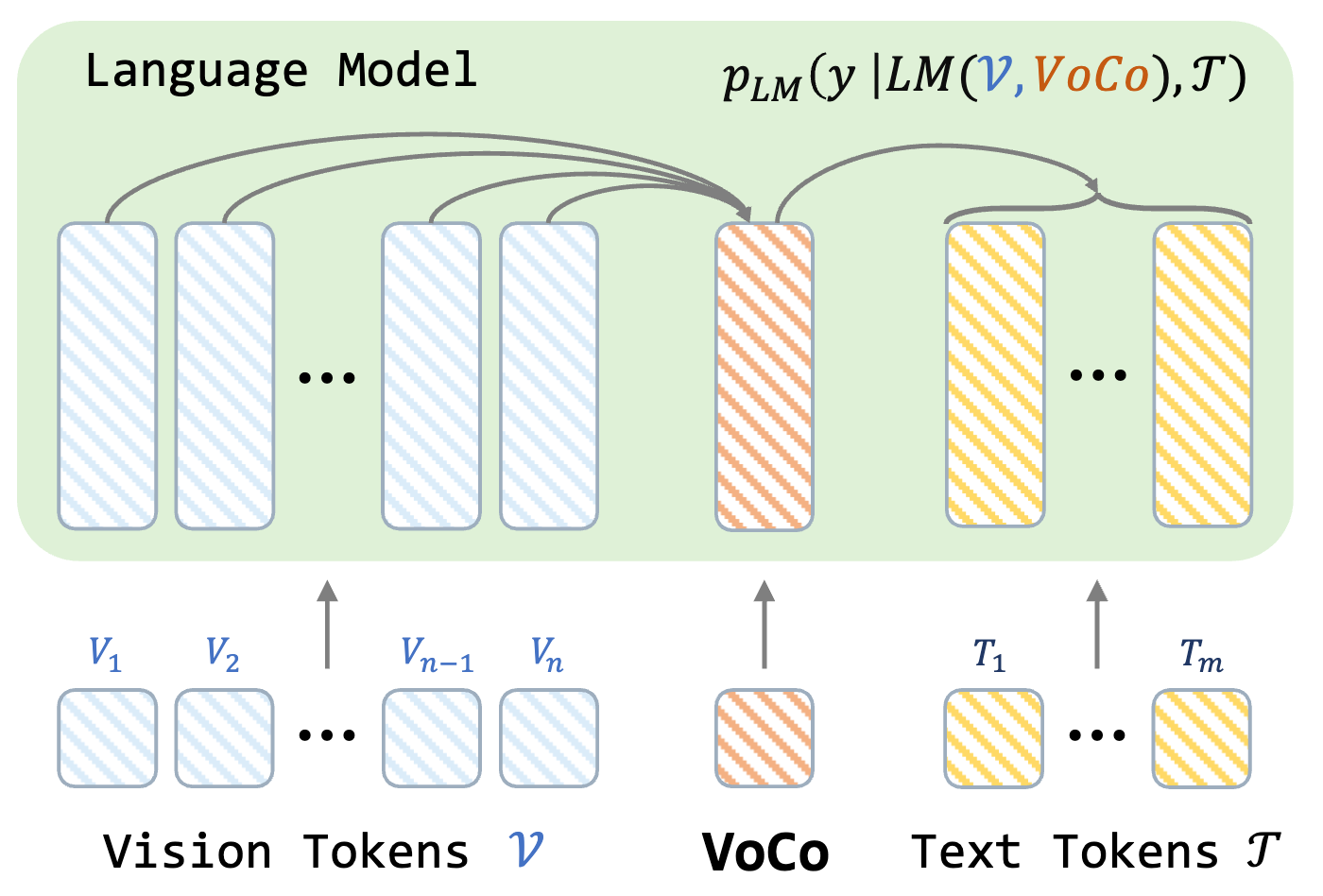
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, Yansong Tang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [PDF] [Project Page] [Code] [AK] [中文解读] Proposed VoCo-LLaMA, an attention-distilled video token compression method enabling video-LLMs to train and inference million-token (1+ hour) videos within a 4k-context LLM. |
|
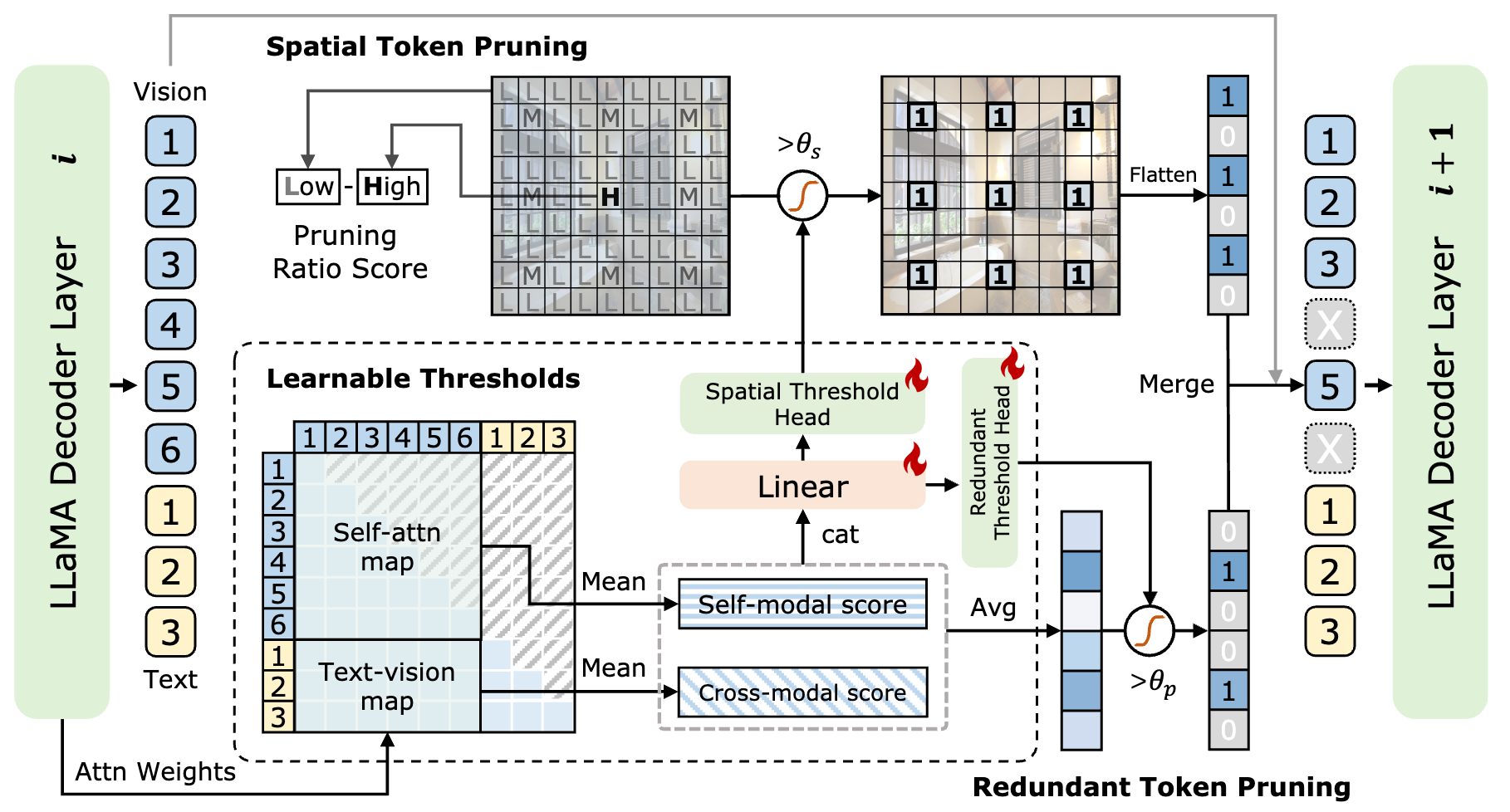
Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-ping Zhang, Yansong Tang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [PDF] [Project Page] Proposed ATP-LLaVA, an efficient MLLM that performs adaptive instance-wise and decoder-layer-wise token pruning with nearly no performance degradation. |
|
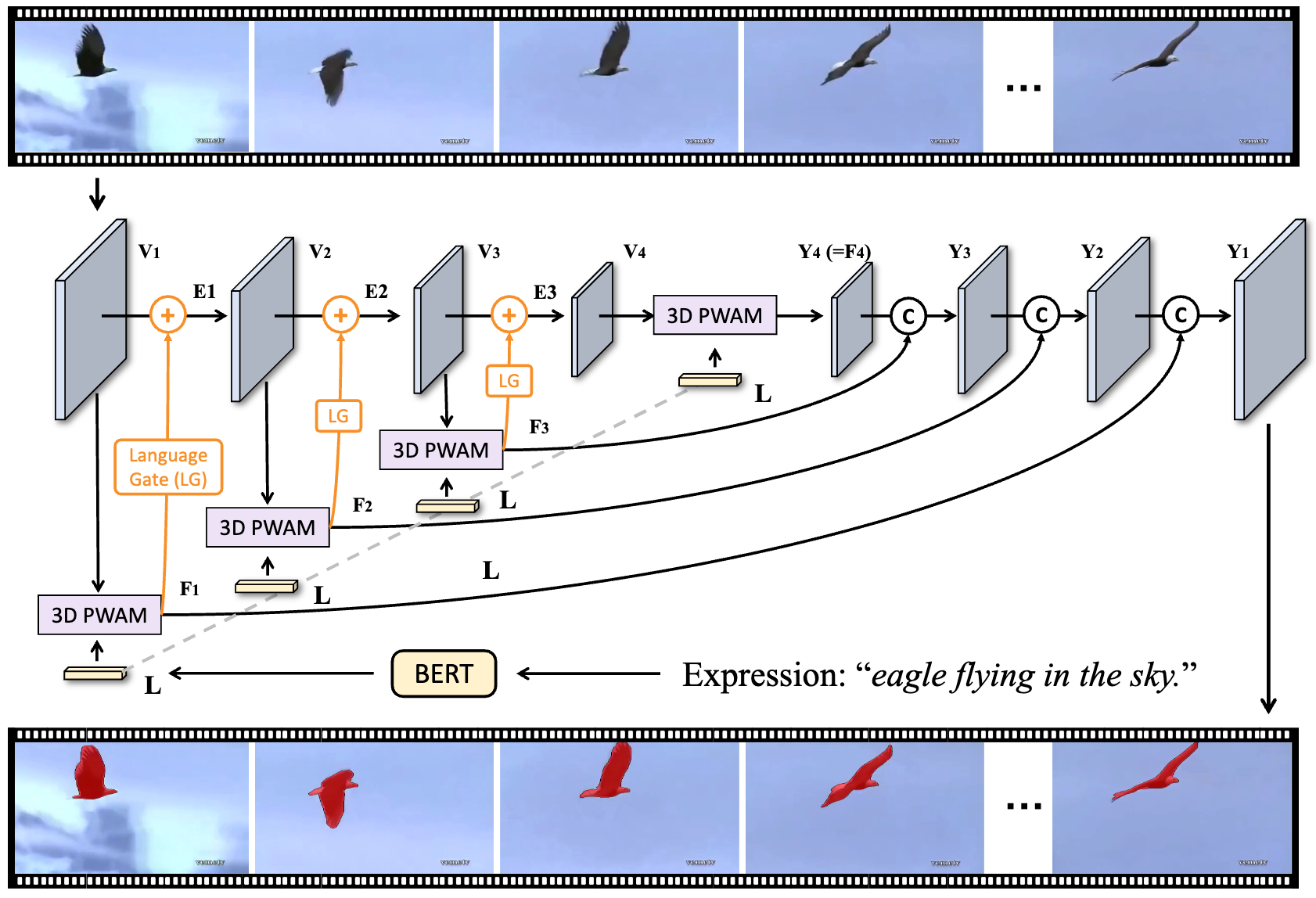
Xubing Ye*, Zhao Yang*, Jiaqi Wang*, Yansong Tang, Kai Chen, Hengshuang Zhao, Philip H.S. Torr IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, IF=20.8), 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [IEEE] [PDF] [Code] [Conference Version] Proposed LAVT, a Transformer-based universal referring image and video segmentation (RIS and RVOS) framework that performs language-aware visual encoding in place of cross-modal fusion post feature extraction. |
|
|
|
|

|
|

|
|
|
|